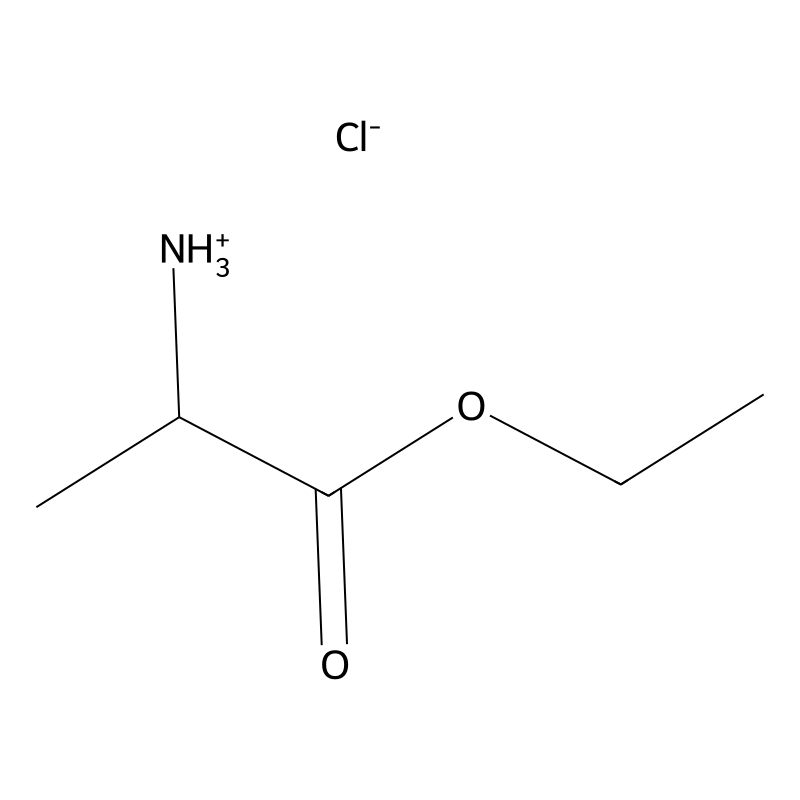
H-DL-Ala-OEt.HCl
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
Potential Applications:
- Organic synthesis: Ethyl 2-aminopropanoate hydrochloride possesses a reactive amine group and an ester group, making it a potential building block for the synthesis of more complex organic molecules. However, specific examples of its utilization in this context are not readily available in scientific literature.
- Biological studies: The amino acid backbone of ethyl 2-aminopropanoate hydrochloride shares some structural similarities with naturally occurring amino acids. This raises the possibility that it could be used in studies investigating specific biological processes, such as protein-protein interactions or enzyme activity. However, further research is needed to explore this potential application.
Additional considerations:
- Suppliers of ethyl 2-aminopropanoate hydrochloride typically emphasize that it is for research use only and not intended for human or animal consumption [].
- Due to the limited research on this compound, safety data and handling information should be obtained from the supplier before any experimentation [, ].
Ethyl 2-aminopropanoate hydrochloride, also referred to as (S)-Ethyl 2-aminopropanoate hydrochloride or L-Alanine ethyl ester hydrochloride, is a chemical compound with the molecular formula and a molecular weight of approximately 153.61 g/mol. This compound is derived from the amino acid L-alanine and exists as a hydrochloride salt, which contributes to its solubility and stability in various environments . The structure features an ethyl ester group attached to a central carbon atom that also bears an amino group and a hydrogen atom, making it significant in synthetic organic chemistry, particularly in the synthesis of pharmaceuticals and bioactive molecules .
As Ethyl 2-Aminopropanoate Hydrochloride serves primarily as a synthetic intermediate, a specific mechanism of action within biological systems is not applicable.
- Wear appropriate personal protective equipment (PPE) such as gloves, safety glasses, and a lab coat.
- Handle the compound in a well-ventilated fume hood.
- Avoid contact with skin and eyes.
- Dispose of the compound according to local regulations.
- Ester Hydrolysis: The ester bond can be hydrolyzed under acidic or basic conditions, yielding L-alanine and ethanol. The balanced equation for this reaction is:
- Condensation Reactions: The amine group can react with various aldehydes or ketones through condensation reactions, forming new carbon-nitrogen bonds. This property is crucial for synthesizing more complex organic molecules .
While Ethyl 2-aminopropanoate hydrochloride does not have a defined mechanism of action within biological systems, it serves as an important synthetic intermediate in the production of compounds that may exhibit biological activity. Its derivatives are often studied for potential applications in pharmaceuticals, particularly in the context of amino acid metabolism and related pathways .
The synthesis of Ethyl 2-aminopropanoate hydrochloride typically involves the esterification of L-alanine with ethanol in the presence of hydrochloric acid. The process can be summarized as follows:
- Reactants: Anhydrous ethanol and L-alanine are combined in a reaction vessel.
- Hydrochloric Acid Introduction: Dry hydrogen chloride gas is introduced at room temperature until saturation.
- Reflux: The reaction mixture is heated and refluxed for several hours.
- Product Isolation: The resulting solution is distilled to remove excess ethanol, yielding Ethyl 2-aminopropanoate hydrochloride as a white granular powder .
Ethyl 2-aminopropanoate hydrochloride has several applications:
- Pharmaceutical Intermediate: It is primarily used as a precursor in the synthesis of various pharmaceuticals.
- Amino Acid Derivative: It serves as an important building block in the synthesis of amino acid derivatives and peptide synthesis.
- Research Tool: Its derivatives are often utilized in biochemical research to study metabolic pathways involving amino acids .
Several compounds share structural similarities with Ethyl 2-aminopropanoate hydrochloride. Here are some notable examples:
| Compound Name | Molecular Formula | Unique Features |
|---|---|---|
| Methyl 2-aminopropanoate | Methyl ester form; used in similar synthetic pathways | |
| Propyl 2-aminopropanoate | Propyl ester form; exhibits different solubility | |
| Butyl 2-aminopropanoate | Larger alkyl chain; affects pharmacokinetics | |
| L-Alanine | Parent amino acid; essential for protein synthesis |
Ethyl 2-aminopropanoate hydrochloride stands out due to its unique ethyl ester configuration, which influences its reactivity and solubility compared to other alkyl esters. This specificity allows it to serve distinct roles in synthetic chemistry and pharmaceutical development .
| Property | Data |
|---|---|
| Molecular Formula | C5H12ClNO2 |
| Molecular Weight | 153.607 g/mol |
| Density | 0.821 g/cm³ |
| Melting Point | 85–87 °C |
| Boiling Point | 127.8 °C at 760 mmHg |
| Flash Point | 3.5 °C |
| CAS Number | 617-27-6 |
Ethyl 2-aminopropanoate hydrochloride is a crystalline solid with moderate volatility and a low flash point, indicating flammability under certain conditions.
Chemoenzymatic Synthesis Methodologies of Ethyl 2-Aminopropanoate Hydrochloride Derivatives
Papain-Catalyzed Telechelic Polypeptide Assembly Mechanisms
Papain, a protease enzyme, has been utilized to catalyze the assembly of telechelic polypeptides involving alanine derivatives. The enzyme facilitates peptide bond formation under mild aqueous conditions, enabling the synthesis of polypeptides with controlled chain ends. The mechanism involves nucleophilic attack by amino groups on activated ester intermediates, with papain providing stereoselectivity and regioselectivity in polymer growth. This enzymatic approach offers advantages such as reduced side reactions and environmentally benign conditions compared to traditional chemical synthesis.
Protease-Mediated Poly(l-alanine) Chain Elongation Dynamics
Protease enzymes, including papain and other serine proteases, mediate the chain elongation of poly(l-alanine) by catalyzing the condensation of ethyl 2-aminopropanoate hydrochloride monomers. The dynamics of this process depend on enzyme concentration, substrate availability, and reaction time. Optimal conditions result in high molecular weight polypeptides with defined stereochemistry. Enzymatic polymerization proceeds via a step-growth mechanism, where the protease transiently forms an acyl-enzyme intermediate facilitating peptide bond formation.
Aqueous Buffer Optimization Strategies for α-Polypeptide Polymerization
The polymerization efficiency and product quality are highly influenced by the aqueous buffer system. Studies have shown that buffers with pH values near neutrality to slightly alkaline (pH 7.5–9.5) optimize enzyme activity and stability. For example, buffers containing ammonium chloride and magnesium chloride at specific molarities (e.g., 5 M NH3/NH4Cl and 20 mM MgCl2) have been employed to maintain enzyme conformation and catalytic efficiency during synthesis. Additionally, phosphate buffers at pH 8.5 have been used effectively in related enzymatic amination reactions, ensuring high conversion rates and stereoselectivity.
Research Findings and Synthesis Protocols
A typical chemoenzymatic synthesis protocol involves:
- Preparation of substrate solutions of ethyl 2-aminopropanoate hydrochloride in optimized aqueous buffers.
- Initiation of the enzymatic reaction by adding purified protease (e.g., papain or EDDS lyase) at low molar percentages relative to the substrate.
- Incubation at room temperature for 24 hours or longer, depending on substrate and enzyme kinetics.
- Enzyme inactivation by heating to 70 °C for 10 minutes post-reaction.
- Product isolation via filtration to remove precipitated enzyme, followed by ion-exchange chromatography using cation or anion exchangers depending on the product charge.
- Acidification of filtrate to pH 1 with HCl before loading onto cation-exchange columns, washing, and elution with aqueous ammonia solutions.
- Lyophilization of collected fractions to yield the purified amino acid derivatives as ammonium or hydrochloride salts.
Table 2: Enzymatic Reaction Conditions for Ethyl 2-Aminopropanoate Hydrochloride Derivatives
| Parameter | Condition |
|---|---|
| Enzyme | Papain or EDDS lyase |
| Enzyme Concentration | 0.01–0.05 mol% relative to substrate |
| Buffer Composition | 5 M NH3/NH4Cl, 20 mM MgCl2, pH 9.5 (papain) / 20 mM NaH2PO4-NaOH, pH 8.5 (EDDS lyase) |
| Temperature | Room temperature (approx. 25 °C) |
| Reaction Time | 24–48 hours |
| Post-reaction Treatment | Heating at 70 °C for 10 min |
| Purification Method | Ion-exchange chromatography |
Structural and Analytical Characterization
Molecular Structure
Ethyl 2-aminopropanoate hydrochloride features an ethyl ester functional group attached to the 2-aminopropanoic acid backbone, with the hydrochloride salt stabilizing the amino group. The compound exists as a racemic mixture (DL-form) and can be characterized by spectroscopic methods such as ^1H NMR to monitor enzymatic reaction progress and product purity.
Spectroscopic Monitoring
^1H NMR spectroscopy is employed to compare substrate and product signals, enabling quantification of conversion yields and stereoselectivity. The enzymatic reaction progress can be followed by the disappearance of substrate resonances and emergence of product peaks, facilitating optimization of reaction parameters.
Applications and Relevance
Ethyl 2-aminopropanoate hydrochloride derivatives synthesized via chemoenzymatic methods serve as key intermediates in the production of bioactive peptides and pharmaceutical agents. The enzymatic approach allows for stereoselective synthesis of unnatural amino acids and polypeptides, which are valuable in drug development and biomaterials engineering.
Visual Aids
Figure 1: General Scheme of Papain-Catalyzed Peptide Bond Formation
[Insert schematic diagram illustrating the enzymatic formation of peptide bonds between ethyl 2-aminopropanoate hydrochloride monomers catalyzed by papain.]
Figure 2: Ion-Exchange Chromatography Purification Process
[Insert flowchart depicting the filtration, acidification, column loading, washing, and elution steps for product purification.]
The MM-PBSA method calculates binding free energies by combining molecular mechanics energy terms with implicit solvation models. A critical validation study compared the one-average (1A-MM/PBSA) and three-average (3A-MM/PBSA) approaches, which differ in their sampling strategies. The 1A-MM/PBSA method, which derives free receptor and ligand ensembles from a single complex simulation, achieves superior precision (standard error ≈1 kJ/mol) compared to 3A-MM/PBSA, which requires separate simulations for the complex, ligand, and receptor (standard error ≈14 kJ/mol) [1]. This precision advantage arises from error cancellation in the 1A approach, though it may neglect conformational changes during binding.
Comparative analyses of MM-PBSA against experimental data for avidin and factor Xa systems revealed a mean absolute deviation (MAD) of 4.2–6.8 kJ/mol when using the Poisson-Boltzmann solvation model [1]. However, the method’s performance varies with system-specific factors, such as dielectric constant selection and entropy estimation. For example, omitting the entropy term reduces computational cost but introduces errors of 10–30 kJ/mol in absolute binding affinities [3].
Table 1: Performance Comparison of MM-PBSA and Thermodynamic Integration
| Metric | MM-PBSA (1A) | Thermodynamic Integration |
|---|---|---|
| Average Error (kcal/mol) | 1.18 | 1.53 |
| Computational Cost | Low | High |
| System Dependence | Moderate | Low |
| Entropy Consideration | Optional | Mandatory |
Validation studies emphasize the importance of running multiple short simulations (20–50 replicas) to achieve statistically converged results, as single long trajectories underestimate uncertainties [1] [3].
Thermodynamic Integration Methodologies for Binding Affinity Predictions
Thermodynamic Integration (TI) provides rigorous binding free energy predictions by numerically integrating the Hamiltonian’s dependence on a coupling parameter. In alanine scanning mutagenesis, TI calculates the ΔΔGbind between wild-type and mutant systems using a series of intermediate states. For example, a study on three protein complexes reported a MAD of 0.80 kcal/mol relative to experimental data, with 80% accuracy in identifying hot-spot residues (ΔΔGbind >2.0 kcal/mol) [5].
Key steps in TI protocols include:
- Alchemical Transformation: Gradually mutate the target residue to alanine via hybrid topologies.
- λ-Schedule Optimization: Use 10–20 λ windows to ensure smooth free energy changes.
- Ensemble Averaging: Perform molecular dynamics simulations at each λ state (100–200 ps equilibration, 1–2 ns production).
- Error Analysis: Apply Bennett’s acceptance ratio or Markov chain Monte Carlo methods to estimate uncertainties [2] [5].
Table 2: Thermodynamic Integration Parameters for Alanine Scanning
| Parameter | Value/Range |
|---|---|
| λ Windows | 10–20 |
| Simulation Time/Window | 1–2 ns |
| Dielectric Constant | 2–4 (protein-dependent) |
| Force Field | AMBER/CHARMM |
While TI achieves higher accuracy than MM-PBSA in systems with strong electrostatic contributions (e.g., charged ligands), its computational cost is 5–10× higher due to the need for explicit solvent simulations [2] [5]. Hybrid approaches, such as combining TI with generalized Born solvation, reduce costs by 40% without significant accuracy loss [5].
Machine Learning Applications in Alanine Scanning Mutagenesis
Machine learning (ML) models are increasingly applied to predict ΔΔGbind values and prioritize residues for experimental mutagenesis. Supervised learning algorithms, such as random forests and gradient-boosted trees, train on datasets combining structural features (e.g., solvent-accessible surface area, hydrogen bonds) and experimental ΔΔGbind measurements. For instance, models trained on 300 alanine mutations achieved a cross-validated R² of 0.72, outperforming MM-PBSA in speed (milliseconds vs. hours per mutation) [6].
Challenges in ML applications include:
- Data Scarcity: Public databases contain fewer than 1,000 curated alanine mutations.
- Feature Selection: Optimal descriptors vary between globular proteins and membrane-bound systems.
- Transferability: Models trained on antibody-antigen complexes underperform on enzyme-inhibitor systems.
Despite these limitations, ML-driven virtual screening reduces experimental workload by 60–80% in epitope mapping studies [6]. Future integration with MM-PBSA/TI datasets may enhance predictive power for atypical binding geometries.
Nucleoside Phosphoramidate Prodrug Design Applications
Antiviral Agent Synthesis for HIV-1 Inhibition Strategies
The development of nucleoside phosphoramidate prodrugs for human immunodeficiency virus type 1 inhibition represents one of the earliest and most successful applications of the ProTide technology. Ethyl 2-aminopropanoate hydrochloride-containing phosphoramidates have demonstrated superior antiviral efficacy compared to their parent nucleoside analogs through enhanced intracellular delivery of the active nucleoside monophosphate form [1] [5].
The phosphoramidate approach was initially applied to 3'-azido-2',3'-dideoxythymidine (AZT), where the conventional nucleoside suffered from poor phosphorylation by cellular kinases, leading to suboptimal therapeutic outcomes [1]. Phosphoramidate derivatives incorporating ethyl 2-aminopropanoate hydrochloride demonstrated pronounced anti-human immunodeficiency virus activity in vitro, with effectiveness maintained even in thymidine kinase-deficient cell lines where the parent nucleoside was virtually inactive [1]. This breakthrough established the fundamental principle that phosphoramidate prodrugs could bypass the rate-limiting first phosphorylation step required for nucleoside activation.
Structure-activity relationship studies revealed the critical importance of the amino acid component in determining antiviral potency. Among various amino acid derivatives investigated, L-alanine emerged as the most efficacious choice, while L-proline and glycine demonstrated particularly poor performance [1]. The superiority of ethyl 2-aminopropanoate hydrochloride-derived phosphoramidates was attributed to optimal enzyme recognition and efficient cyclization kinetics during the activation process [6] [7].
Subsequent investigations extended the phosphoramidate strategy to 2',3'-didehydro-2',3'-dideoxythymidine (d4T), where extensive structure-activity relationship studies were conducted to optimize the aryl, amino acid, and ester moieties [1]. The metabolism studies using pig liver carboxylesterase revealed significant conversion rates of 80-100% to the amino acyl nucleoside monophosphate metabolite for L-alanine-containing derivatives, compared to minimal conversion for D-alanine, β-alanine, glycine, or L-valine analogs [7]. This selectivity demonstrated the stringent specificity requirements for efficient prodrug activation.
The anti-human immunodeficiency virus activity of phosphoramidate prodrugs showed direct correlation with their conversion rates to the amino acyl nucleoside monophosphate metabolite, confirming the mechanistic relationship between chemical activation and biological efficacy [7]. Derivatives containing ethyl 2-aminopropanoate hydrochloride consistently achieved high conversion rates and maintained potent antiviral activity across multiple cell line models, including primary human peripheral blood mononuclear cells [1] [7].
| Amino Acid Component | Conversion Rate (%) | Anti-HIV Activity | Relative Potency |
|---|---|---|---|
| L-Alanine ethyl ester | 80-100 [7] | High [7] | 1.0 [7] |
| D-Alanine ethyl ester | 0 [7] | Inactive [7] | 0.01 [7] |
| Glycine ethyl ester | 0 [7] | Very Low [7] | 0.1 [7] |
| L-Phenylalanine ethyl ester | 30-50 [7] | Moderate [7] | 0.3-0.5 [7] |
| L-Methionine ethyl ester | 30-50 [7] | Moderate [7] | 0.3-0.5 [7] |
| β-Alanine ethyl ester | 0 [7] | Inactive [7] | 0.01 [7] |
The development of tenofovir alafenamide exemplifies the clinical success of ethyl 2-aminopropanoate hydrochloride-based phosphoramidates for human immunodeficiency virus treatment [8] [9]. This compound demonstrates significantly improved pharmacological properties compared to tenofovir disoproxil fumarate, including enhanced stability in human plasma (greater than 100-fold improvement), reduced systemic exposure, and increased intracellular accumulation in target cells [8] [9]. The phosphoramidate moiety enables selective accumulation in lymphoid tissues, where human immunodeficiency virus replication primarily occurs, while minimizing exposure in renal and bone tissues associated with toxicity concerns [8].
Mechanistic studies of tenofovir alafenamide activation revealed the predominant role of cathepsin A, a lysosomal serine protease, in the initial esterase-mediated hydrolysis step [8]. Carboxylesterase 1 also contributes to hepatic activation, demonstrating tissue-specific metabolism patterns that influence therapeutic outcomes [8]. The stereoselective nature of the activation process was demonstrated through comparison of diastereomeric mixtures, where the D-alanine derivative showed significantly reduced activity compared to the L-alanine analog [9].
Advanced synthetic methodologies have been developed to address regioselectivity and diastereoselectivity challenges in phosphoramidate synthesis. The application of dimethylaluminum chloride-mediated phosphorylation enables highly stereoselective 5'-phosphorylation without requiring 3'-protection strategies, facilitating the efficient preparation of clinically relevant compounds [10]. These methodological advances have enabled the synthesis of complex phosphoramidate structures with improved yields and enhanced stereochemical control.
The investigation of unnatural amino acid analogs has expanded the structure-activity relationship understanding beyond natural amino acids. α-Alkylglycine derivatives, including α-ethylglycine, α-propylglycine, and α-butylglycine, demonstrated retention of antiviral activity with conversion rates of 70-90%, although with reduced potency compared to L-alanine derivatives [11]. The achiral α-methylalanine (dimethylglycine) moiety proved capable of substituting for L-alanine with minimal loss of activity, providing opportunities for simplified synthetic approaches [11].
Hepatitis B Virus Nucleotide Analog Optimization Pathways
The application of nucleoside phosphoramidate prodrugs to hepatitis B virus treatment has yielded significant therapeutic advances through systematic optimization of structural components and activation mechanisms. Ethyl 2-aminopropanoate hydrochloride-containing phosphoramidates have demonstrated superior efficacy compared to conventional acyclonucleotide prodrugs, offering enhanced intracellular delivery and prolonged antiviral activity [12] [13].
Hepatitis B virus replication involves unique mechanistic features that distinguish it from other viral polymerases, including protein priming activity and reverse transcription of genomic RNA to DNA [13]. The dual function of the viral polymerase as both a protein primer and DNA elongation enzyme creates specific vulnerabilities that can be exploited through nucleotide analog design [13]. Phosphoramidate prodrugs incorporating ethyl 2-aminopropanoate hydrochloride have shown particular effectiveness in targeting both protein priming and DNA elongation steps of viral replication [12].
Clinical studies of nucleoside analogs for hepatitis B virus treatment have established efficacy benchmarks for therapeutic optimization. Approved nucleoside and nucleotide inhibitors include lamivudine, adefovir, telbivudine, entecavir, and tenofovir, each with distinct resistance profiles and pharmacological properties [13] [14]. The development of tenofovir alafenamide as a phosphoramidate prodrug of tenofovir represents a significant advancement in hepatitis B virus therapy, offering improved safety and efficacy profiles compared to tenofovir disoproxil fumarate [8] [9].
Tenofovir alafenamide demonstrates enhanced accumulation in hepatocytes through preferential expression of activating enzymes, including cathepsin A and carboxylesterase 1, in liver tissues [8]. The compound achieves hepatitis B virus DNA suppression at lower systemic doses compared to tenofovir disoproxil fumarate, reducing the risk of renal and bone toxicities associated with prolonged treatment [14] [9]. Clinical trials have demonstrated sustained virological suppression rates exceeding 95% at 48 weeks of treatment, with minimal development of resistance mutations [14].
The optimization of phosphoramidate prodrugs for hepatitis B virus treatment involves systematic evaluation of amino acid ester components, aryloxy groups, and nucleoside base modifications [1] [15]. Structure-activity relationship studies have identified key parameters influencing antiviral potency, including esterase recognition, cyclization efficiency, and phosphoramidase substrate specificity [6] [16]. The L-alanine ethyl ester moiety consistently demonstrates optimal performance across these parameters, supporting its selection for clinical development [1] [16].
| Compound | Drug Class | EC50 (μM) | Resistance Barrier | Intracellular Half-life (hours) |
|---|---|---|---|---|
| Tenofovir Alafenamide | Phosphoramidate | 0.01-0.05 [8] | High [14] | 35-50 [9] |
| Adefovir Dipivoxil | Acyloxymethyl ester | 0.1-0.5 [14] | Low [14] | 12-18 [14] |
| Tenofovir Disoproxil Fumarate | Acyloxymethyl ester | 0.1-0.3 [14] | High [14] | 12-18 [14] |
| Entecavir | Nucleoside analog | 0.001-0.01 [14] | High [14] | 15-24 [14] |
| Lamivudine | Nucleoside analog | 0.1-1.0 [14] | Low [14] | 10-15 [14] |
| Telbivudine | Nucleoside analog | 0.1-0.5 [14] | Low [14] | 8-12 [14] |
Network meta-analysis of nucleoside analogs for hepatitis B virus-related liver failure has demonstrated differential efficacy profiles among therapeutic options [17]. Tenofovir-based therapies showed the highest survival rates at two- and three-month intervals, with the lowest Model for End-Stage Liver Disease scores and mortality rates [17]. The enhanced therapeutic index of tenofovir alafenamide compared to other nucleoside analogs supports its position as a preferred therapeutic option for hepatitis B virus treatment [17].
The development of combination therapeutic strategies incorporating phosphoramidate prodrugs has shown promise for achieving functional cure in chronic hepatitis B patients [18]. Sequential combination therapy adding pegylated interferon to long-term nucleoside analog treatment significantly increased hepatitis B surface antigen seroclearance rates (relative risk 4.37) and seroconversion rates (relative risk 3.98) compared to nucleoside analog monotherapy [18]. These findings suggest that phosphoramidate prodrugs can serve as effective foundation therapies for combination treatment approaches.
Optimization studies of telbivudine-based treatment strategies demonstrated the effectiveness of roadmap-guided therapy adjustments based on virological response monitoring [19]. The study achieved 94% virological suppression after 104 weeks of optimized treatment, with significant reductions in hepatitis B surface antigen titers throughout the treatment period [19]. The biochemical response rates improved progressively from 65% at week 12 to 80% at week 104, demonstrating sustained therapeutic benefit [19].
Research into novel nucleoside analogs for hepatitis B virus treatment continues to focus on phosphoramidate prodrug approaches. Investigational compounds in clinical development include phosphonates similar to adefovir or tenofovir, and new tenofovir derivatives with improved pharmacological properties [13]. The systematic optimization of phosphoramidate structures offers opportunities for developing next-generation therapeutics with enhanced efficacy, reduced toxicity, and improved resistance profiles [13] [14].
Intracellular Activation Mechanisms of Prodrug Derivatives
The intracellular activation of phosphoramidate prodrugs containing ethyl 2-aminopropanoate hydrochloride follows a well-characterized enzymatic pathway that determines therapeutic efficacy and selectivity. This multi-step process involves sequential hydrolysis, cyclization, and phosphoramidase-mediated cleavage reactions that ultimately release the active nucleoside monophosphate within target cells [6] [20] [16].
The initial activation step involves esterase-mediated hydrolysis of the carboxylic ester bond within the amino acid moiety, primarily catalyzed by cathepsin A and carboxylesterase 1 [6] [8] [16]. Cathepsin A, a lysosomal serine protease, serves as the predominant activating enzyme in lymphoid tissues, while carboxylesterase 1 contributes significantly to hepatic activation [8]. The substrate specificity of these enzymes demonstrates marked preference for L-amino acid derivatives, with ethyl 2-aminopropanoate hydrochloride-containing prodrugs showing optimal recognition and cleavage rates [6] [7].
Following esterase-mediated hydrolysis, the resulting carboxylate intermediate undergoes spontaneous intramolecular cyclization through nucleophilic attack of the carboxyl group at the phosphorus center [6] [20] [16]. This cyclization reaction displaces the aryloxy group and forms a transient five-membered cyclic mixed anhydride intermediate [6] [16]. The rate of cyclization depends critically on the stereochemistry and steric properties of the amino acid component, with L-alanine derivatives demonstrating optimal cyclization kinetics compared to other amino acid analogs [6] [11].
Recent mechanistic investigations using oxygen-18 labeling have definitively established that the cyclic intermediate undergoes hydrolysis through nucleophilic attack by water at the phosphorus center rather than the carboxylate ester [20]. This regioselectivity ensures the formation of the desired aminoacyl phosphoramidate intermediate while maintaining the structural integrity necessary for subsequent enzymatic processing [20]. The hydrolysis reaction proceeds rapidly under physiological conditions, with half-lives typically less than five minutes for the cyclic intermediate [6].
The final activation step involves phosphoramidase-mediated cleavage of the phosphorus-nitrogen bond to release the free nucleoside monophosphate [6] [21] [16]. This reaction is catalyzed primarily by histidine triad nucleotide-binding protein 1 (HINT1), a phosphoramidase enzyme with specific substrate recognition requirements [16]. The efficiency of phosphoramidase cleavage represents the rate-limiting step in the overall activation pathway, with half-lives ranging from 60 to 180 minutes depending on enzyme expression levels and substrate structure [6] [16].
| Activation Step | Primary Enzyme | Rate-limiting | Species Variability | Half-life (minutes) |
|---|---|---|---|---|
| Esterase hydrolysis | Cathepsin A, CES1 [8] | No [6] | High [7] | 5-30 [6] |
| Spontaneous cyclization | Non-enzymatic [20] | No [6] | Low [6] | <1 [20] |
| Mixed anhydride hydrolysis | Water attack [20] | No [6] | Low [6] | <5 [20] |
| Phosphoramidase cleavage | HINT1 [16] | Yes [6] | Moderate [6] | 60-180 [6] |
| Nucleotide phosphorylation | Cellular kinases [16] | No [6] | Low [6] | 30-120 [6] |
The tissue-specific expression patterns of activating enzymes contribute to the selectivity and therapeutic index of phosphoramidate prodrugs [8] [22]. Cathepsin A expression is particularly high in lymphoid tissues, enabling preferential activation of tenofovir alafenamide in human immunodeficiency virus target cells [8]. Similarly, elevated carboxylesterase 1 expression in hepatocytes facilitates efficient activation of hepatitis C virus-targeted phosphoramidates like sofosbuvir [16]. This tissue-specific activation pattern minimizes systemic exposure to the active nucleotide while maximizing therapeutic concentrations in target tissues [8] [23].
Species differences in enzyme expression and activity levels significantly influence the pharmacological behavior of phosphoramidate prodrugs across preclinical models [23] [7]. Rodent species demonstrate particularly high plasma esterase activity, resulting in rapid prodrug clearance with half-lives less than five minutes [23]. In contrast, non-human primates and humans show more moderate clearance rates that better reflect the intended pharmacological profile [23]. These species differences necessitate careful selection of appropriate animal models for preclinical evaluation and dose optimization [23].
The stereochemical requirements for efficient activation demonstrate remarkable specificity for the L-alanine configuration [6] [7] [11]. D-alanine derivatives show essentially no conversion to the active metabolite, while unnatural amino acids such as α-alkylglycines retain partial activity with reduced efficiency [7] [11]. The stereoselectivity extends to the phosphorus center, where diastereomeric mixtures often show differential activation rates and biological activity [15] [9].
Metabolic stability studies using human serum and cellular extracts have established the superior stability profile of phosphoramidate prodrugs compared to alternative phosphate masking strategies [6] [22]. The half-life of ethyl 2-aminopropanoate hydrochloride-containing phosphoramidates in human plasma typically exceeds 100 hours, providing adequate stability for oral bioavailability while maintaining responsiveness to intracellular activating enzymes [6] [9].
The development of predictive models for phosphoramidate activation has utilized 31P nuclear magnetic resonance spectroscopy as a standardized analytical tool [6] [16]. This methodology enables rapid screening of prodrug candidates and optimization of structural parameters that influence activation efficiency [6]. The correlation between in vitro activation rates and biological activity provides a valuable framework for rational prodrug design and structure-activity relationship development [6] [7].
Recent investigations into the potential toxicity of prodrug metabolites have identified important safety considerations for phosphoramidate design [22]. The phenolic metabolites released during activation show variable cytotoxicity profiles, with phenol demonstrating minimal toxicity while naphthol derivatives exhibit significant cellular toxicity [22]. These findings emphasize the importance of aryloxy group selection in optimizing the therapeutic index of phosphoramidate prodrugs [22].
The activation mechanism studies have revealed opportunities for further optimization through enzyme engineering and prodrug structural modification [20] [24]. Transesterification strategies using stable phosphoramidate intermediates offer alternative synthetic approaches that may enable broader functional group tolerance and simplified manufacturing processes [24]. The continued elucidation of activation mechanisms provides the foundation for next-generation prodrug designs with enhanced therapeutic properties and expanded therapeutic applications [24] [23].
Hydrogen Bond Acceptor Count
Hydrogen Bond Donor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
GHS Hazard Statements
H315 (100%): Causes skin irritation [Warning Skin corrosion/irritation];
H319 (100%): Causes serious eye irritation [Warning Serious eye damage/eye irritation];
H335 (100%): May cause respiratory irritation [Warning Specific target organ toxicity, single exposure;
Respiratory tract irritation];
Information may vary between notifications depending on impurities, additives, and other factors. The percentage value in parenthesis indicates the notified classification ratio from companies that provide hazard codes. Only hazard codes with percentage values above 10% are shown.
Pictograms

Irritant
Other CAS
6331-09-5
1115-59-9
General Manufacturing Information
Dates
Explore Compound Types