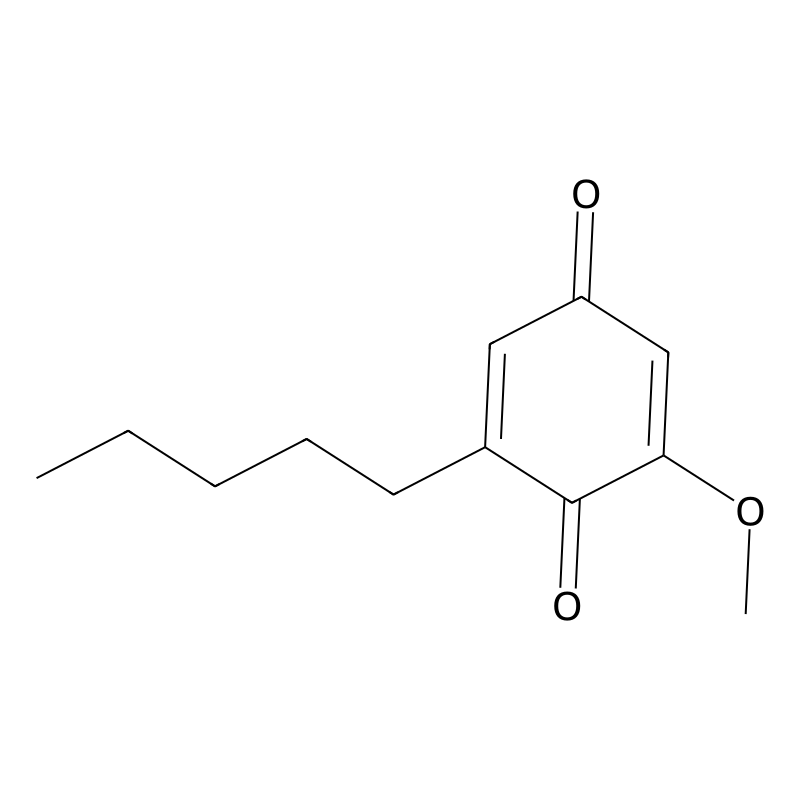
Primin
Content Navigation
CAS Number
Product Name
IUPAC Name
Molecular Formula
Molecular Weight
InChI
InChI Key
SMILES
Synonyms
Canonical SMILES
Primin (2-methoxy-6-pentyl-1,4-benzoquinone, CAS 15121-94-5) is a naturally occurring benzoquinone derivative recognized as the primary contact allergen in Primula obconica and a highly active biological scaffold. In procurement and industrial research, it is primarily sourced as a high-purity analytical standard for dermatological patch testing, a reference inhibitor for 5-lipoxygenase (5-LOX) assays, and a synthetic precursor for developing hypoxia-activated antineoplastic prodrugs. Its specific 2-methoxy and 6-pentyl substitution pattern dictates its high lipophilicity and target binding affinity, making it a critical baseline material for structure-activity relationship (SAR) studies comparing quinone-mediated antimicrobial, antiprotozoal, and immunological responses[1]. Procurement of synthetic Primin is driven by the need for exact molar dosing in these applications, where structural deviations or crude mixtures compromise assay integrity .
Generic substitution of Primin with crude botanical extracts or closely related benzoquinones fails due to strict structural and dosing requirements in its primary applications. In diagnostic formulations, substituting synthetic Primin with crude Primula extracts introduces severe concentration variability, leading to false-negative readings or unintended active sensitization in patients [1]. In biochemical screening, altering the alkyl chain length—such as substituting with 2-methoxy-6-heptyl-1,4-benzoquinone or thymoquinone—drastically shifts lipid-water partition coefficients, altering 5-LOX binding affinity and eliminating its specific allergenic elicitation profile[2]. Therefore, precise procurement of >98% pure synthetic Primin is mandatory to ensure exact molar dosing and reproducible assay calibration.
Purity-Linked Reproducibility in Diagnostic Formulations
For dermatological diagnostics, crude botanical extracts cannot substitute for synthetic Primin. Crude Primula obconica extracts cause up to 17% false diagnostic reactions and carry a high risk of active sensitization due to uncontrolled dosing. In contrast, formulating with >98% pure synthetic Primin at a standardized 0.01% concentration in petrolatum ensures reproducible elicitation of allergic responses without the primary irritation observed at concentrations of 1% or higher [1].
| Evidence Dimension | Diagnostic accuracy and irritation threshold |
| Target Compound Data | Synthetic Primin (0.01%): Reproducible elicitation, 0% primary irritation |
| Comparator Or Baseline | Crude botanical extract: Up to 17% false reactions, high sensitization risk |
| Quantified Difference | Synthetic formulation eliminates the 17% false reaction rate and prevents active sensitization. |
| Conditions | European baseline series patch testing in human subjects. |
Procurement of high-purity synthetic Primin is strictly required for formulating reliable diagnostic patch tests, as botanical sourcing is diagnostically invalid.
Precursor Suitability for Antineoplastic Prodrug Synthesis
Primin serves as a necessary baseline scaffold for synthesizing less toxic antineoplastic prodrugs. Unmodified Primin exhibits severe systemic toxicity, proving lethal at 30 mg/kg i.p. in murine models. However, when Primin is used as a precursor to synthesize 2-methoxy-6-n-pentyl-hydroquinone-di-(2'-tetrahydropyranyl) ether, the resulting prodrug maintains potent S-180 sarcoma inhibition while successfully eliminating the characteristic systemic toxicity of the raw quinone[1].
| Evidence Dimension | In vivo systemic toxicity vs. antineoplastic efficacy |
| Target Compound Data | Primin-derived THP-ether prodrug: Maintained tumor inhibition, low toxicity |
| Comparator Or Baseline | Unmodified Primin: Lethal toxicity at 30 mg/kg i.p. |
| Quantified Difference | THP-protection of the Primin scaffold preserves efficacy while bypassing lethal systemic toxicity. |
| Conditions | Murine models for S-180 sarcoma and Ehrlich carcinoma. |
Buyers developing quinone-based antineoplastics should procure Primin as a starting scaffold for THP-protection, enabling controlled hypoxic activation while bypassing the severe handling toxicities of the raw compound.
Direct Enzymatic Benchmarking in 5-LOX Inhibition
In anti-inflammatory drug screening, Primin provides a highly potent, naturally derived benchmark for 5-lipoxygenase (5-LOX) inhibition. In cell-free assays measuring leukotriene B4 (LTB4) formation via human recombinant 5-LOX, Primin demonstrated an IC50 of 1.4 ± 0.6 µM. This is nearly equivalent to the clinical standard 5-LOX inhibitor Zileuton, which exhibited an IC50 of 1.1 ± 0.7 µM under identical conditions .
| Evidence Dimension | IC50 for LTB4 formation (5-LOX inhibition) |
| Target Compound Data | Primin: 1.4 ± 0.6 µM |
| Comparator Or Baseline | Zileuton (Clinical Standard): 1.1 ± 0.7 µM |
| Quantified Difference | Primin performs within a 0.3 µM margin of the clinical standard Zileuton. |
| Conditions | Human recombinant 5-LOX enzyme assay. |
Primin serves as a highly effective, structurally distinct positive control for calibrating in vitro anti-inflammatory and lipoxygenase screening workflows.
Comparative Potency in Antiprotozoal Screening
Primin is utilized as a high-potency reference standard in neglected tropical disease research. In vitro screening against Leishmania donovani and Leishmania amazonensis reveals that Primin achieves IC50 values ranging from 0.711 µM to 1.25 µM. This demonstrates significantly higher in vitro potency than the standard clinical therapeutic Amphotericin B, which yields an IC50 of 5.08 µM in comparable leishmanicidal assays [1].
| Evidence Dimension | In vitro IC50 against Leishmania species |
| Target Compound Data | Primin: 0.711 µM - 1.25 µM |
| Comparator Or Baseline | Amphotericin B: 5.08 µM |
| Quantified Difference | Primin is approximately 4 to 7 times more potent in vitro than Amphotericin B. |
| Conditions | In vitro antiprotozoal screening assays against Leishmania promastigotes. |
For laboratories screening antileishmanial agents, Primin provides a critical high-potency reference standard to validate assay sensitivity against established clinical drugs.
Formulation of Standardized Dermatological Patch Tests
Primin is the required analytical standard for formulating the European baseline series patch tests for contact dermatitis. Procuring >98% pure synthetic Primin allows manufacturers to achieve the exact 0.01% petrolatum dilution required to elicit reproducible allergic responses while strictly avoiding the primary irritation and false-positive rates associated with crude botanical extracts [1].
Synthesis of Hypoxia-Activated Antineoplastic Prodrugs
Where direct administration of quinones is limited by systemic toxicity, Primin serves as an ideal starting scaffold for prodrug synthesis. By converting Primin into tetrahydropyranyl (THP) ethers, medicinal chemists can retain the compound's potent S-180 sarcoma inhibition while effectively masking the quinone moiety to bypass lethal in vivo toxicities[2].
Positive Control in Anti-Inflammatory 5-LOX Screening
Due to its potent inhibition of leukotriene B4 formation (IC50 = 1.4 µM), Primin is procured as a reliable, naturally derived positive control for 5-lipoxygenase (5-LOX) assays. It provides a non-indole, non-hydroxyurea structural benchmark that performs with near-equivalence to the clinical standard Zileuton .
Reference Standard in Neglected Tropical Disease Assays
In antiprotozoal drug discovery, Primin is utilized as a high-potency in vitro reference standard. Its sub-micromolar efficacy against Trypanosoma and Leishmania species (outperforming Amphotericin B in vitro) makes it a critical baseline compound for calibrating assay sensitivity when screening novel leishmanicidal or trypanocidal libraries[3].
References
- [1] Patch testing with the European baseline series and 10 added allergens. Contact Dermatitis, 2021.
- [2] Synthesis and Antitumour Activity of the Primin (2-methoxy-6-n-pentyl-1,4-benzoquinone) and Analogues. Letters in Drug Design & Discovery, 2007.
- [4] Antituberculotic and Antiprotozoal Activities of Primin, a Natural Benzoquinone: In vitro and in vivo Studies. Planta Medica.
XLogP3
Hydrogen Bond Acceptor Count
Exact Mass
Monoisotopic Mass
Heavy Atom Count
UNII
GHS Hazard Statements
H302 (100%): Harmful if swallowed [Warning Acute toxicity, oral];
H312 (100%): Harmful in contact with skin [Warning Acute toxicity, dermal];
H317 (100%): May cause an allergic skin reaction [Warning Sensitization, Skin];
H332 (100%): Harmful if inhaled [Warning Acute toxicity, inhalation];
H334 (100%): May cause allergy or asthma symptoms or breathing difficulties if inhaled [Danger Sensitization, respiratory];
Information may vary between notifications depending on impurities, additives, and other factors. The percentage value in parenthesis indicates the notified classification ratio from companies that provide hazard codes. Only hazard codes with percentage values above 10% are shown.
Pictograms


Irritant;Health Hazard
Other CAS
Wikipedia
Dates
Explore Compound Types









